
Stay Up to Date
Subscribe to our newsletter
This work is the result of a collaboration between Horizen Labs and various universities and other companies, including Graz University of Technology and TACEO GmBH. For more details we refer to the full paper.
The evaluation of hash functions is a major bottleneck in many modern proving systems. While using fast and standardized hash functions such as SHA-2 or SHA-3 is certainly possible, these more classical constructions are often not well-suited for the underlying proving system. This results in a fast plain evaluation but expensive proof generations.
Therefore, in recent years, many new hash functions tailored towards settings of computational integrity have been designed. These are usually called “arithmetization-oriented” or “circuit-friendly”. One of the most popular of these constructions is the Poseidon hash function, which is nowadays used in many different frameworks and projects in the ZK space.
Here we introduce a new family of hash functions called Griffin. It uses a novel cryptographic permutation, consisting of a classical so-called substitution-permutation network (SPN) and a new approach which we called Horst.
Some components in modern (zero-knowledge) proving systems require the evaluation of hash functions, or more precisely chains of hash function evaluations. For example, in Plonky2, this step needs a significant amount of the total time required to generate a proof. Hence, symmetric cryptographers have recently started to design hash functions specifically for this use case, in order to make modern proving systems more efficient.
What arguably started with derivatives of the MiMC permutation, such as the Poseidon hash function, has now become a rather active area of research. Multiple hash functions are now proposed every year, each of them making different tradeoffs regarding their performance.
The efficiency of a specific hash function in zero-knowledge settings (or, more generally, in computational integrity use cases) can mostly be defined by using the two following metrics.
Generally speaking, components with a low degree when written down as a mathematical function are more efficient in (zero-knowledge) proving systems. For example, the function f(x) = x³ is generally more efficient than g(x) = x⁸²⁶³¹⁷. Hence, the idea for the Poseidon permutation was to only use low-degree components and to iterate them until a sufficiently large degree is reached in order to withstand cryptographic attacks. Of course, this means that potentially many of these iterations are necessary in order to reach a very large degree, since each iteration is itself of low degree.
Hash functions like Poseidon2, Neptune, and GMiMC-based approaches follow the same approach. While many iterations of low-degree components (or “rounds” in symmetric cryptography terms) are needed, these functions usually provide a good plain performance (i.e., a fast computation time on software).
In 2018, a group of researchers proposed the Friday hash function. The main observation in that paper is that a high-degree evaluation can be represented by a low-degree constraint. In particular, the authors use the fact that the generally high-degree inverse function f(x) = x^(-1) can be rewritten as f(x) = x^(-1) = y if and only if x*y = 1 for a nonzero x (some details are omitted for simplicity). This means that while using a high-degree component when actually computing the hash function, the corresponding constraint in the proving system can be of low degree. As a result, while the plain performance (or speed) of the hash function is in general worse, its circuit representation can be more efficient.
This approach was later also used by the hash functions Rescue, Griffin, and Anemoi.
While deriving low-degree constraints from high-degree functions is certainly possible,the cost of actually computing a hash output can quickly become very high. This can be seen for example with Rescue, where the high-degree component needs to be evaluated many times until the final output is reached.
The main idea of Griffin is therefore to limit the use of this high-degree component. Indeed, we only need it a few times in the entire hash function call, and can therefore reach a plain performance which is much better than that of Rescue and even close to Poseidon in some instances.
In more detail, the round function of Griffin is split in two parts. The first part is similar to a classical substitution-permutation network, which essentially means that a nonlinear function is applied to each input element in this part separately. One of these nonlinear functions is a high-degree one which allows for a low-degree constraint. This part is responsible for increasing the degree of the permutation quickly. The second part of the round function uses a new cryptographic component which we call “Horst”. It is similar to a classical Feistel network, but replaces the additive component by a multiplicative one.
The approach used in Griffin has two main advantages. First, the degree grows as quickly as in similar functions such as Rescue, which means that only a small number of rounds is required to reach the maximum degree. Moreover, we have only one high-degree component in each round and the Horst part of the state has a constant degree independent of the actual instantiation. This means that Horst is much faster than Rescue or Anemoi, while offering the same advantages regarding low-degree constraints and cryptographic security.
Many different arithmetization techniques exist in literature. For the Griffin paper, our initial goal was to be efficient in the R1CS technique, where essentially the number of degree-2 constraints is measured. Hence, we will also focus on this comparison in the following. However, we note that Griffin is also efficient when using other arithmetization approaches such as AIR and the more general Plonk(ish).
When starting with the design of Griffin, our main goal was to achieve much better circuit efficiency than Poseidon. At the same time, we wanted to retain a certain level of plain performance.
In the following charts we compare Griffin to its competitors.
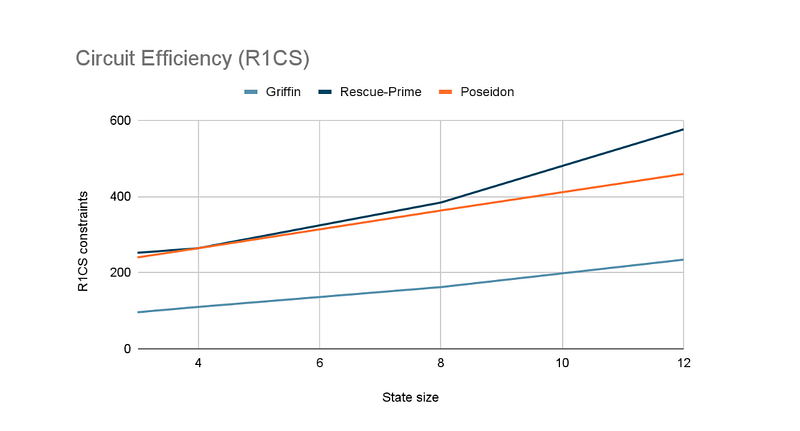
As we can see from the first chart, Griffin is on the same level as Poseidon regarding its plain performance, and it is faster than Rescue-Prime. However, in accordance with the main goal of the paper, Griffin has a clear advantage in terms of circuit efficiency. This comparison only shows its R1CS metrics, but Griffin is also efficient in AIR and Plonk. We refer to the full paper for more details about Griffin in these two settings.
When the number of constraints in a certain scenario needs to be minimized, Griffin can be the right choice. In particular, Griffin is very efficient when using the R1CS arithmetization technique. Considering that its plain performance is similar to that of Poseidon for many instantiations, replacing Poseidon with Griffin leads to fewer constraints while still maintaining a certain level of plain performance.
Markus Schofnegger, mschofnegger@horizenlabs.io
Monolith: https://eprint.iacr.org/2023/1025
Reinforced Concrete: https://eprint.iacr.org/2021/1038
Tip5: https://eprint.iacr.org/2023/107
Poseidon: https://eprint.iacr.org/2019/458
Poseidon2: https://eprint.iacr.org/2023/323
Rescue: https://eprint.iacr.org/2019/426
Griffin: https://eprint.iacr.org/2022/403
Anemoi: https://eprint.iacr.org/2022/840

About Horizen Labs Tech
Technical blog of Horizen Labs — zero-knowledge cryptography research and engineering.
Is Your Organization Vulnerable?
Get A Free and Instant Quantum Risk CheckBLOG

Running a CBOM scanner before a Quantum Threat Assessment is the most common and expensive mistake in quantum-security migration. Without a prioritized threat model, scan results are either unmanageable or incomplete. Here's why the assessment has to come first, and what the right sequence looks like.

The academic cryptography community has crossed a threshold: at Eurocrypt 2026, quantum resistance was no longer a topic on the agenda — it was the baseline assumption behind every serious research contribution. Here's what that shift looks like from the inside, and what it means for anyone building cryptographic infrastructure today.

A Cryptographic Bill of Materials (CBOM) scan is the right quantum-readiness step for organizations with large, distributed cryptographic estates: financial institutions, cloud providers, defense contractors. For protocol-native organizations, cryptography-centric startups, and SaaS-dependent enterprises, it isn't. The right Phase 1 is a Quantum Threat Assessment that maps actual risk surface before any tooling is deployed.