
Stay Up to Date
Subscribe to our newsletter
The Horizen Labs engineering team improved the algorithm of coins selection used by Horizen mainchain (Zend client).
While we are about to release EON on Mainnet, as the first EVM compatible sidechain in the Horizen Ecosystem, the team hasn’t stopped improving what we still consider the center of our universe, Zend.
We would like to share the way we have improved the algorithm of coins selection used by Horizen mainchain (Zend client). In this article we start with a description of the root issue that led the improvement activity, then continue with the analysis and the approach to design and implementation of the new algorithm; eventually we conclude with some benchmarked results.
The Horizen mainchain has embraced the UTXO (unspent transaction output) model, that is a stateless model where every transaction creates one or many outputs (new coins) based on the inputs (feeding coins) it spends. For example, if we think of a generic transaction, the sender will have to specify as inputs the owned UTXOs to use, while the outputs will be the amount that he wanted to send to the receiver, the paid fees, and possibly the change.
Zend, the official Horizen mainchain client, acts as a network node of the Zen cryptocurrency.
Just like Bitcoin, it comes with a local wallet that can be used for sending different types of transactions using the command line. To mention one example, sending $ZEN coins to another user through what we call an RPC command.
It all began with an internal ticket (what a thriller novel intro, no?); it was reporting a failure during the attempt to send coins. In short, the eventual symptom was the transaction being rejected by the node, after being built based on the coins selection performed by the associated algorithm. For the end user, this meant the coins were not sent to the recipient, and any retry was pointless.
Well, in the first place understanding if the issue was a bug and in case it was, fixing it, possibly taking the chance to perform some refactoring and improvements.
Wait, wait, don’t rush, here are the links to our pull requests on GitHub (feature, benchmark) but probably it’s better if you continue reading, then take a coffee (or maybe two) and later move to the code.
Did we succeed in fixing the bug and improving our application?
Yes, for sure we did! Long story short, we were able to find the root cause of the issue and fix it, making the algorithm more robust. In addition, we pushed on modifying the algorithm and some auxiliary functions in order to get additional benefits.
To anticipate a few results, here are some key achievements:
As soon as we started working on this task, we organized the activity going through the following steps:
Instead of trying to manually reproduce the issue, we have followed a TDD (test driven development) approach; by adding a new Python script in our existing regression test framework, we made the failure repeatable. This helped a lot in the initial analysis and during the development phase.
Simply the mandatory part: analyzing the code to get the root cause of the issue. Taking advantage of the Python script mentioned above, we went through a meticulous process of code inspection, debugging and profiling.
In the end, we’ve found the bug in the lack of a constraint on the total size of the selected coins, resulting in the creation of an oversized transaction when too many coins were selected. Moreover, during this investigation we were able to detect some inefficiencies and flaws both in the pre-processing phase of the coins selection algorithm and in the fee management procedure; hence we grabbed the opportunity to clean and improve them.
Now let’s try to formulate the coins selection problem in a more scientific way:
Coins selection can be modeled as a discrete optimization problem:
Input variables:
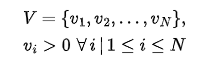


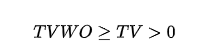

Output variables:

Derived output variable (can be computed from selection set):
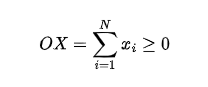

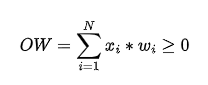
Cost function:
Constraints:
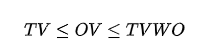
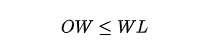
(if you didn’t, just go back and print in your brain those names like V, W, TV, etc; they will be used throughout the article!)
So, going back to the bugged algorithm, we found it was not considering the weight limit constraint; hence, in some cases (quite seldom telling the truth, but still happening) the selection was affecting so many small coins that the final transaction was later rejected, being abnormally big; but if a good portion of those many small coins was replaced with fewer bigger coins, the eventual total size would have been admissible and the transaction accepted.
So, given the above finding and the problem modelization, we implemented a two-solvers algorithm, that is to say:
SW is the one acting first, its purpose is to find a suboptimal solution and to identify an admissible value for TargetValueWithOffset to be passed to the next solver.
Here below the associated procedure:
This solver runs iteratively at different increasing levels of TargetValueWithOffset, starting from TargetValue (hence no change) until a predefined maximum value. As mentioned above, this solver generally produces a suboptimal solution but the positive aspects are that it’s extremely fast and it serves as a quick initializer for the second solver.
B&B is the solver running after SW, its purpose is to find an optimal solution.
Its implementation uses a binary tree, to be considered as the combination of exclusion/inclusion of each coin. B&B is based on a depth-first brute force exploration strategy, empowered by two additional optimization features, namely backtracking and bounding. Starting with an “all coins unselected” setup, the algorithm recursively explores the tree (from biggest coin towards smallest coin) opening two new branches, the first one excluding the current coin, the second one including the current coin; when a leaf is reached, the output variables are checked to identify if an improved solution (with respect to the temporary optimal one) is found and eventually marked as the new temporary optimal solution.
Just to have a better understanding, let’s have a look at what a full depth-first brute force exploration strategy means:
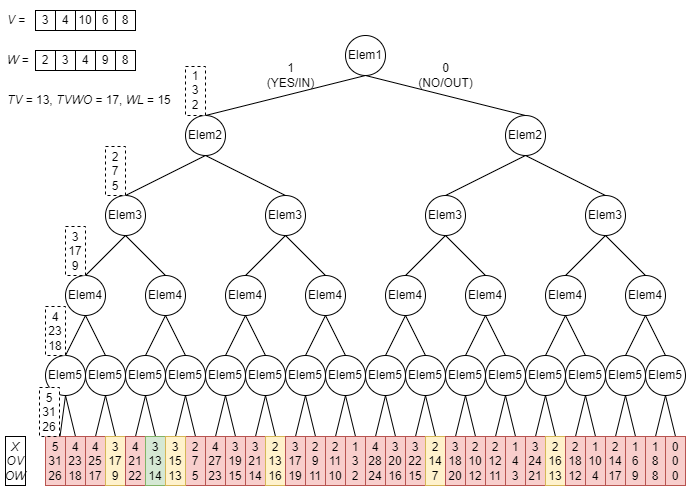
Now let’s consider the first part of backtracking feature, stating “if OV>TVWO or OW>WL, then prune the exploration of this branch, since the constraints are irrevocably broken and cannot recover through adding other coins” (because adding any coin would result in an increase of both OV and OW)…

…and the second part of backtracking feature, based on the assumption “if OV summed to the value obtained by including all the following coins does not exceed TV, then prune the exploration of this branch” (because even including all the remaining coins we would not be able to met the constraint TV≤OV):
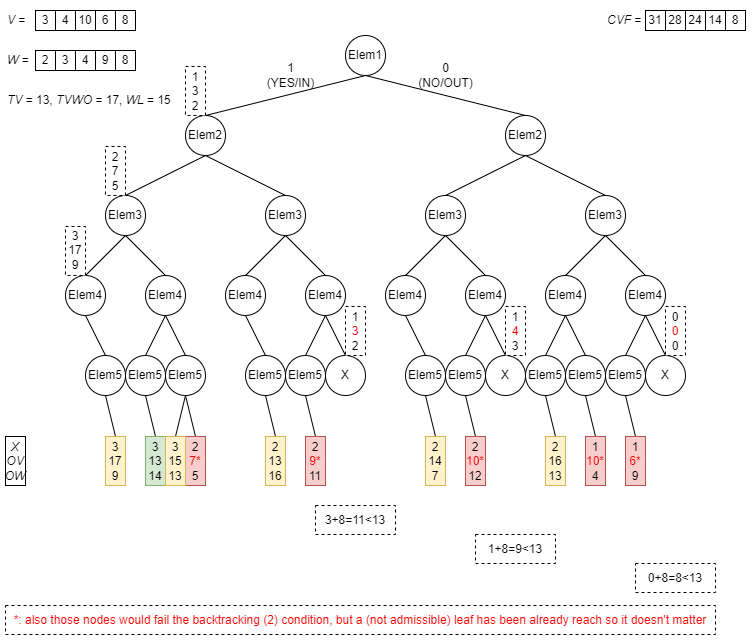
Finally, the bounding feature allows us to optimize the exploration even further, considering “if OX summed to the quantity of following coins still to be included does not improve the temporary optimal solution, then prune the exploration of this branch” (because even including all the remaining coins we would not be able to have a better value for OX):
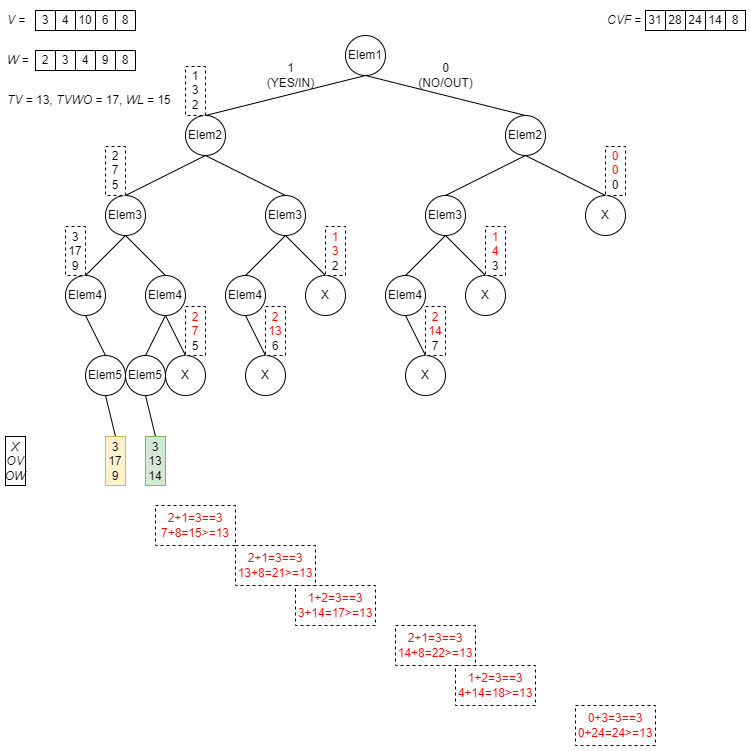
With those features, we can achieve a very significant reduction of tree exploration, avoiding making useless computations and having the solver to run more efficiently in terms of speed and resources consumption.
Conversely to SW, B&B solver runs significantly slower because it aims at finding an optimal solution to the selection problem. This led us to control its execution with a configurable timeout; as soon as the timeout is hit, the B&B run stops and its partial result is compared (using the cost function) against the one previously obtained by SW; the best among them is considered the final solution.
For the sake of completeness, the possibility to handle coins weights was allowed through the introduction of some auxiliary functions responsible for estimating the size of the transaction excluding the inputs (i.e. the selected coins); this allowed us also to improve the fee management procedure, avoiding selection of unneeded coins that previously resulted in higher fee rates.
In the second phase of the development, we decided to write a Python script for measuring in some way the quality of what we were implementing; that would have been our compass when it came down to implementation details, and it helped a lot in the fine tuning of the code. In the end it was also a good way to show our boss we are the good guys!
So, the script provides the generation of some randomized wallets, with different attributes:
Then several different transactions are performed using a stored randomly generated set of amounts (so in this way we were able to have randomness, but in a repeatable way), keeping track of the following metrics:
Having a significantly high number of runs, in order to get a good sample size and averaging the results, we obtained for the old algorithm:

and for the new one:

with the following overall comparison (as relative percentage differences) table:

Looking at the results we can see that:
So, here we are, at the end of our story. The overall achievement is really satisfying, and we are also very proud of the analytic approach we set up for the resolution of this task; the new feature is just waiting for a monitored run on a more realistic and stressed test environment (private or public testnet) but the feelings seem promising and positive.
But since we are never totally done, possible next steps we can define could be:
And why not add something more to this nice list? Any thoughts on this? Any feedback or proposal would be really really appreciated! Then, in case you missed it or scrolled down here because of low patience, here again the links to our pull requests on GitHub (feature, benchmark).
Thanks for reading, see you in the next episode!
Author: Giacomo Pirinoli, gpirinoli@horizenlabs.io
Secure Your Enterprise Against the Quantum Threat
Talk to an ExpertBLOG

Federated Learning keeps data private, but it still relies on trust. Clients or aggregators can cheat.

Private cloud backups are a vital tool in today’s digital landscape. Backups, in general, allow users to store important information…

Why the next wave of adoption won’t be “more transparent,” but “private by default without losing compliance.”
Subscribe to our newsletter