
Stay Up to Date
Subscribe to our newsletter
TL;DR:
Federated Learning keeps data private, but it still relies on trust. Clients or aggregators can cheat, poison updates, free-ride, or tamper with results. Verifiable Federated Learning (VFL) adds proofs (via zero-knowledge proofs and/or trusted execution environments (TEEs)) so parties can verify data usage, training behavior, and aggregation correctness.
Today, verifying aggregation is the most practical/near-term win, while full verifiable training is still expensive and hard. Blockchains can act as a public verifier + audit log, and zkVerify can make proof verification dramatically cheaper, improving real-world feasibility.
We are currently living in the AI era and, as everyone of you probably knows, AI products are enabled thanks to Machine Learning models. Now, as a company, we particularly care about the privacy of data, and it has turned out that a specific field of Machine Learning, namely Federated Learning, is of particular interest.
Let’s consider a scenario where multiple entities need to train a common model: with the classic ML approach, these entities will send the data to a resourceful server performing the training on this merged dataset. This is fine if the datasets don’t contain sensitive information or if we consider the server as a trusted entity that’s not curious, but this is a strong assumption. What happens instead in those scenarios where the entities are not willing to share the dataset with the training server? Just to mention a couple, take into consideration healthcare and finance.
Well, Federated Learning is the answer.
This is a Machine Learning approach introduced by Google in 2016, where every client trains the same model locally, and these partial local models are sent to an aggregator, which aggregates them, obtaining a global model. This global model is then checked against a stopping criterion that, if met, yields the final model; otherwise, it will be redistributed and another round of training will take place, starting from that model and the same dataset.
Federated Learning framework, for a general round t:
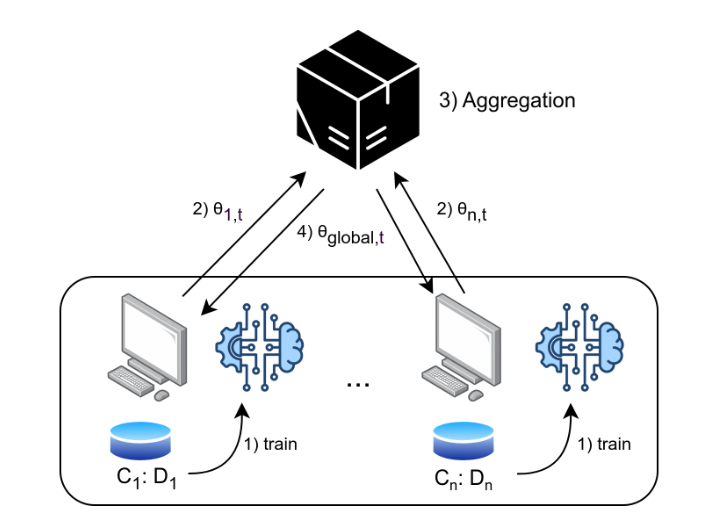
Where C(i) denotes client i, D(i) denotes the dataset of client i, 𝜃(i,t) denotes the weights of client i at round t, and 𝜃(global,t) denotes the resulting model after the aggregation at round t.
It is clear how, in this framework, the privacy of the datasets is preserved, as they never leave the clients’ machines.
This vanilla framework, per se, already offers these strong privacy guarantees, but there are some nuances, and one of these is that since many entities are involved, the attack surface is increased. The following are some of the most well-known attacks:
As you can see, there are many attacks where the central point is the lack of trust concerning the entities; specifically, we can’t be sure that they are behaving as they should, following the protocol specifications.
But notably, it has been shown in many research efforts that a way to mitigate part of those classes of attacks is by integrating verifiable technologies into the vanilla federated learning framework, obtaining a sounder framework called Verifiable Federated Learning. These technologies are zero-knowledge proofs and trusted execution environments, the former relying on cryptographic assumptions, the latter relying on hardware assumptions.
Both of them come with advantages and disadvantages, but their integration within the FL framework can really strengthen behavioural guarantees.
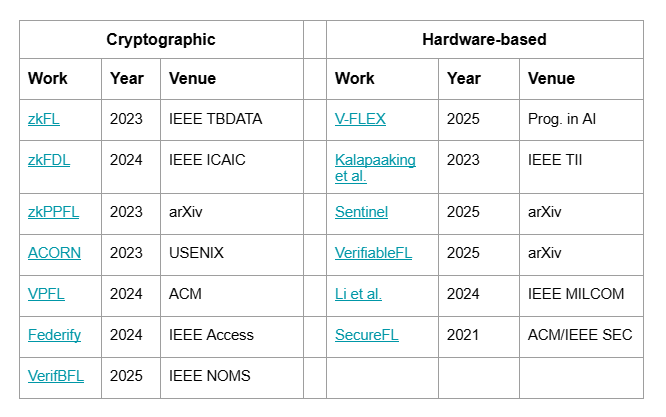
This is a real state-of-the-art topic in the verifiable computing field, and we managed to make a systematization effort by analyzing 13 papers that tried to tackle this problem. These papers were all published from 2023 to 2026; in the following two comprehensive tables, we divide them by the technologies being used.
But where are the main challenges related to verifiability in Federated Learning? Well, we can find three delicate points:
Making those three claims verifiable can help mitigate certain attacks illustrated above.
First, implementing verifiable claims in data usage can help mitigate data poisoning attacks, as clients may be required to provide evidence that they are using specific data that could have been committed previously, along with additional guarantees regarding policies or certain properties of the data. Verifiability in data usage can be broadened by also considering the gradients sent to the aggregator as data, requiring the client to provide additional constraints on their properties, like norm bounds, thereby helping to mitigate model poisoning attacks.
Furthermore, implementing verifiable claims during the training phase can help mitigate model poisoning and free riding, as clients are required to provide evidence proving that they complied with the agreed-upon training procedure. This means that if they deviate from the procedure or send arbitrary gradients without accompanying evidence, the aggregator can detect and flag such behaviour as misbehaviour. This also prevents free riding, meaning that if a client does not provide evidence of the computation, it can be flagged as a free rider and excluded from the protocol by the next iteration.
Eventually, enforcing verifiable claims during aggregation can prevent global model tampering and selective dropping, as the aggregator is required to provide evidence proving that all gradients from the expected clients were included in the aggregation, along with an integrity constraint on the computation to prevent any interference with the procedure.
The following table presents the state of the art of the most recent works, where VD stands for Verifiability in Data, VT stands for Verifiable Training, and VA stands for Verifiable Aggregation:

An ideal verifiable federated learning framework would implement verifiability across all three dimensions, but the current verifiability mechanisms are better suited to some claims than to others, as can be noticed from the table.
Verifiable training is the most computationally intensive phase of the protocol, and current zero-knowledge proving schemes struggle with the circuitization of non-linear layers that are typical in modern architectures. Trusted execution environments (TEEs) face similar challenges, as current enclave solutions struggle to run the entire training procedure within the enclave. What is instead really feasible with current technologies is proving the aggregation, given its linear nature that fits well into zero-knowledge circuits and runs smoothly within enclaves up to a certain number of client contributions.
Verifiability in data usage appears to be feasible, as it would require proving the usage of certain committed data for dataset integrity, which amounts to nothing more than Merkle proofs with additional constraints, along with some range proofs regarding the properties of the gradients. However, it currently does not seem to be a priority in any of the implementations surveyed.
Notably, the blockchain infrastructure and its transparency property prove to be of interest in this framework, serving as an enabler for verifiability along two dimensions:

As can be noticed from the table, the main usage of the blockchain turns out to be as the medium for proofs generated off-chain. This, of course, comes at a cost that increases as the number of clients increases and as the complexity of the computation to be proven increases.
The following table provides the average verification cost for a light computation to be proven using Groth16 (values as of Feb, 16):

As can be seen, there are Layer 2 solutions that are already quite cheap.
An even cheaper solution would be relying on our blockchain, recently launched on Mainnet: zkVerify!
Considering a proof for the same calculation to be verified on zkVerify, we can achieve a cost of 0.0003 USD, which is a decimal order of magnitude less compared to the cheapest Layer 2 option!
But this does not end here. Given the sparsity of framework proposals in the solutions we have analyzed, we have formalized a common framework that could potentially standardize the VFL one, setting a common ground for all stakeholders interested in this area, including researchers, developers, and those willing to contribute to existing solutions.
Stay tuned for that!

About Horizen Labs Tech
Technical blog of Horizen Labs — zero-knowledge cryptography research and engineering.
Is Your Organization Vulnerable?
Get A Free and Instant Quantum Risk CheckBLOG

Running a CBOM scanner before a Quantum Threat Assessment is the most common and expensive mistake in quantum-security migration. Without a prioritized threat model, scan results are either unmanageable or incomplete. Here's why the assessment has to come first, and what the right sequence looks like.

The academic cryptography community has crossed a threshold: at Eurocrypt 2026, quantum resistance was no longer a topic on the agenda — it was the baseline assumption behind every serious research contribution. Here's what that shift looks like from the inside, and what it means for anyone building cryptographic infrastructure today.

A Cryptographic Bill of Materials (CBOM) scan is the right quantum-readiness step for organizations with large, distributed cryptographic estates: financial institutions, cloud providers, defense contractors. For protocol-native organizations, cryptography-centric startups, and SaaS-dependent enterprises, it isn't. The right Phase 1 is a Quantum Threat Assessment that maps actual risk surface before any tooling is deployed.